 Cart ( )
Cart ( )AI self-learning: How RLAIF technology changes model alignment
2024/7/25 14:25:11
Views:
Recently, the achievements and attention of Master of Laws (LLM) have risen sharply, accompanied by the arrival of the "summer" of artificial intelligence. The training methods of models are also reviving with the aim of obtaining the most optimal and high-performance models as quickly as possible. Although most of these are achieved through large-scale implementations-more chips, more data, more training steps-many teams have been focusing on how to train these models more efficiently and intelligently to achieve the desired results.
The training of LLM usually includes the following stages:
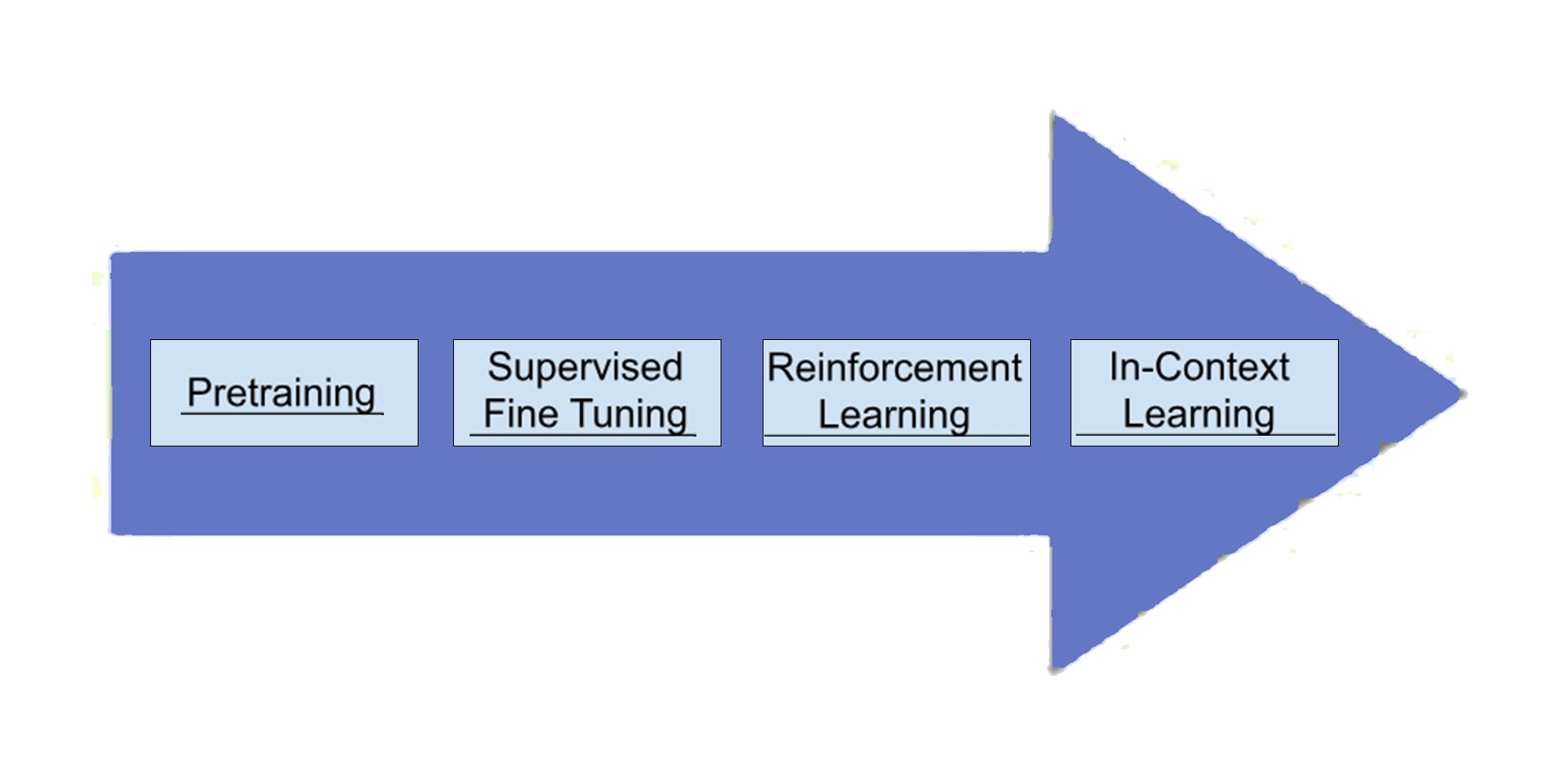
1. Pre-training: This initial stage transforms the model from a set of inert neurons into a basic language generator. The model absorbs a large amount of data (such as the entire Internet), but the output is usually meaningless.
2. Supervised Fine-Tuning (SFT): This stage enhances the model's generation ability, making its output more coherent and useful. SFT teaches the model to generate helpful, useful, and reasonable content by providing specific examples. After completion, the model can be deployed for production.
3. Reinforcement Learning (RL): This stage enhances the model's ability to go beyond explicit instructions by learning users' implicit preferences and desires through labeled preference data.
4. Contextual Learning: Also known as prompt engineering, this technique allows users to directly influence model behavior during reasoning. Users can fine-tune the model's output to suit specific needs and contexts through methods such as constraints and N-shot learning.
In addition, there are many other methods and stages that can be incorporated into special training processes.
Introduction of Reward and Reinforcement Learning
Humans are good at pattern recognition and can usually learn and adapt without deliberate effort. Our intellectual development can be seen as a continuously increasing complex pattern recognition process. Children learn not to jump into puddles after experiencing negative consequences, similar to how LLMs go through SFT. Similarly, teenagers observing social interactions learn to adjust their behavior based on positive and negative feedback-the essence of reinforcement learning.
Key Components of Reinforcement Learning Practice:
1. Preference Data: Reinforcement learning in LLMs typically requires multiple example outputs and a prompt/input to show "gradients." For instance, in RLHF, human users might be provided with a prompt and two examples and asked to choose which they prefer, or they might be given an output and asked to improve it, with the improved version considered the "preferred" option.
2. Reward Model: The reward model is trained directly on preference data, with each response assigned a scalar value indicating its "rank" within the set. The reward model is then trained to predict these scalar values for new input-output pairs.
3. Generator Model: This is the final expected product. During reinforcement training, the generator model generates an output, which is then scored by the reward model, and the reward is fed back to the algorithm to determine how to alter the generator model. For example, with positive rewards, the algorithm updates the model to increase the likelihood of generating a given output; with negative rewards, it does the opposite.
In the LLM field, RLHF has been a dominant force. By collecting vast amounts of human preference data, RLHF has significantly improved LLM performance. However, this method is costly, time-consuming, and susceptible to biases and vulnerabilities.
Understanding RLAIF: An Overview of Using AI Feedback to Scale LLM Alignment
The core idea behind RLAIF is: If LLMs can generate creative text formats such as poems, scripts, or even code, why can't they learn by themselves? This self-improvement concept promises to achieve unprecedented levels of quality and efficiency, surpassing the limitations of RLHF. This is precisely what researchers have achieved through RLAIF.
The innovation of RLAIF lies in its ability to automatically generate preference labels on a large scale without relying on human input. Although all LLMs ultimately derive from human-generated data, RLAIF uses existing LLMs as "teachers" to guide the training process.
RLAIF Methods:
1. Contextual Learning and Prompt Engineering: Through contextual learning and carefully designed prompts, preference information is obtained from the teacher LLM. These prompts provide context, examples, and samples to be evaluated.
2. Chain of Thought Reasoning: Chain of Thought (CoT) prompts are used to improve the teacher LLM's reasoning ability, allowing the teacher to make more detailed preference judgments.
3. Addressing Position Bias: To reduce the impact of response order on teacher preferences, RLAIF averages preferences obtained from multiple prompts with different response orders.
Imagine an already well-trained AI as the teacher. The teacher tests the student by rewarding certain actions and responses. The student continuously improves its behavior through reinforcement learning in these tests.
Advantages of RLAIF:
1. Evaluating Synthetic Preference Data: RLAIF uses "self-reward" scores to compare the generation probabilities of two responses under contrastive prompts, reflecting the alignment degree of each response.
2. Direct Preference Optimization (DPO): Using self-reward scores to optimize the student model, encouraging it to generate responses that align with human values.
Practical Applications and Advantages of RLAIF
RLAIF's versatility extends to tasks such as summarization, dialogue generation, and code generation. Research shows that RLAIF can achieve comparable or even better performance than RLHF while reducing reliance on human annotations.
Furthermore, RLAIF opens the door to future "closed-loop" LLM improvements. Student models become more consistent through RLAIF, in turn serving as more reliable teacher models for subsequent RLAIF iterations, forming a positive feedback loop without additional human intervention.
How to Utilize RLAIF?
If you already have an RL pipeline, leveraging RLAIF is relatively simple:
1. Start with a set of prompts designed to elicit the desired behavior.
2. Create two slightly different versions of each prompt, emphasizing different aspects of the target behavior.
3. Capture the student LLM's responses to each prompt variation.
4. Create meta-prompts to elicit preference information from the teacher LLM for each prompt-response pair.
5. Use the preference data generated in the existing RL pipeline to guide the student model's learning and optimization.
Challenges and Limitations
Despite its potential, RLAIF faces challenges. The accuracy of AI annotations remains a concern, as biases in the teacher LLM can propagate to the student model. Additionally, studies show that models aligned with RLAIF sometimes produce factually inconsistent or less coherent responses, necessitating further exploration of techniques to improve the quality of generated text.
Emerging Trends and Future Research
The emergence of RLAIF has sparked exciting research directions, such as exploring fine-grained feedback mechanisms, integrating multimodal information, applying curriculum learning principles in RLAIF, and investigating the potential of positive feedback loops in RLAIF, as well as incorporating real-world feedback to enhance quality.
Conclusion: RLAIF as a Stepping Stone to Coordinated AI Development
RLAIF offers a powerful and effective method for LLM alignment, with significant advantages over traditional RLHF methods. Its scalability, cost-effectiveness, and self-improvement potential bring great hope for the future of AI development. While acknowledging current challenges and limitations, ongoing research is actively paving the way for a more reliable, objective, and ethical RLAIF framework. As we continue to explore this exciting frontier, RLAIF will become a stepping stone towards a future where LLMs seamlessly integrate with human values and expectations, fully unlocking the potential of AI to benefit society.
Related Information




-

-
Phone
+86 135 3401 3447 -
Whatsapp
